広告に関するなにか: Top 5 Trends in Digital Out of Home
IABのブログポスト、Top 5 Trends in Gigital Out of Homeを読んだ。DOOHというのは初めて聞いた言葉だったのでちょっと記事を拾ってみた。
「IABが考える、2015に掴んでおきたい5つのトレンド」的な記事。
DOOHとは
Digital Out of Home (or “DOOH” as the channel is commonly referred) encompasses a variety of screen shapes, sizes, and levels of interactivity. From digital billboards and signs on taxis, to digital signage at airport gates and gyms and waiting rooms, these varieties underline a necessary bridge between context and location in relevance and favorable recall - vital components of any media campaign.
上記の記事からの引用部分を読んでみるとDOOHは様々なサイズや形のスクリーンが含まれる。デジタルビルボード(渋谷の駅前のあれとか)、タクシーの屋根についている(これはニューヨークの話)デジタルなサイネージから、空港やジムなどにあるデジタルサイネージなどがそれである的なことが書いてあるので、ニュアンス的にはデジタルサイネージよりも広い意味を込めて使われていることがわかる。更にこれらの特徴としてコンテキストとロケーションの間をうまく橋渡しをしてくれるというようなことが書いてあるので、ただの電子掲示板みたいなものとは区別されている。ただし、ここでいうコンテキストが消費者個人のコンテキストを指すものなのか、もう少し大きなシチュエーション的なコンテキスト(たとえばジムであればそこにいる人々は何かしら健康に興味があるというコンテキストが得られる)のことを指すのかは書かれていない。
Trend1: Corss-platform trageting opportunities are on the rise
ユーザーが持ち歩いているモバイルデバイスがリッチになってきているので、DOOHはより高度にパーソナライズができるようになるであろうと。NFCやビーコンなどを使って、ユーザーのデバイスから情報を受け取ってDOOH側で最適な広告を提供する、というようなストーリーが書かれている。
Trend2: DOOH will provide increasingly relevant messages in locations that matter.
これとかこれによると、ひとは家にいるよりも、外出中のほうが様々なメッセージに対する受容性が高くなるというレポートがあるようだ。この特性をうまく活かし、デジタルサイネージのような既存のスクリーンを使いつつも、DOOH的なロケーション&コンテキストアウェアな広告を提供することによって、ユーザーの関心度を高めることができるようになっていくであろう、もしくはそういう取り組みが増えていくであろうという感じだろうか。
このパートを読んでいてデジタルサイネージとDOOHの違いがなんとなくイメージついてきた。デジタルサイネージはあくまでスクリーンであって、DOOHは屋外にあるスクリーンを利用したコンテキスト&ロケーションアウェアな広告手法、ということなんだろうと思う。
Trend3: Data is (literally) where it's at, locally and programmatically.
DOOHもRTBで買えるようになるであろうという話が書かれている。パーミッションやIDのフラグメンテーション問題はいったん置いとくとたしかに
iphone -(nfcとか?)-> デジタルサイネージ-(internet)-> ssp -> dsp
な感じの流れの結果、落札された広告をデジタルサイネージに表示、みたいなことができるという論理が成り立つ。
しかし、↑の図では、ibeaconだとスマホ側からサーバーに通信しなくてはならないので、という理由でなんとなくnfcと書いてみたものの、nfcでほんとにできるんだろうか。というのは若干疑問が残る。(nfcを調べてみれば済む話なんだけれども)
Trend4: Out of Home creates a unique canvas for top-notch creativity.
いままでにない新しい体験をユーザーに対してもたらすことができるであろうという話。いきなり話が雑になったきがするがw
Trend5: There is a rise of new measurement and addressability opportunities in DOOH.
これも若干雑な話で「これからこの分野は成長性していくぜ!」という話w
タイトルにあるnew measurementとかaddressability opportunitiesというのは広告事業者や技術者としてすごく興味をひかれたり期待を寄せたりするのは、すごくわかる。
おわりに
DOOHとは?最近のトレンドとは?という記事だった。実際、IABではDOOH Taskforceというのを立ち上げたと書かれている。活動内容は明記されていないけれども。
パーソナライズされた広告がデジタルサイネージに表示される・・・って、昔見たSF映画みたいな世界でドキドキ感がある。
広告に関するなにか:Spotifyのパーソナライゼーションの話
Personalization at Spotify using Cassandra
広告の話ではないけど、Spotifyのパーソナライゼーションの話ということで。Cassandraを使って大量のデータをベース多くのユーザーに低レイテンシな、プレイリストのパーソナライゼーションを提供してますよ。その裏側を少し紹介しますよという話。
プレイリストのレコメンデーションの難しさの一例として、メタルが好きな2人のひとがいて、再生している楽曲やプレイリストは全く同じだとしても、片方のひとは子供がいるから夜や家ではメタルは聴きたくない。もう片方のひとはそんなこと気にせずいつでもメタルを聴きたい。みたいなケースでレコメンデーションの挙動をいかに最適化するのか、という話が挙げられている。そこで出てくるのがレコメンデーションのパーソナライゼーションでしょうと。
で、中身を読んだんだけど、実際にはパーソナライゼーションの話ではなくてそのためのアーキテクチャやデータベースのモデリングの話だったのであしからず。
アーキテクチャ
見づらいけど・・・
Log ▶▶ Kafka -> HDFS -> Apache Crunch
▼ ▼
▼ <- Cassandra(Entity Metadata Store)
▼ ▼
Storm -> Cassandra(User Profile Store)
Kafkaにユーザーのイベントログを流し込み、そこから2つの経路に分岐。
- HDFSにデータを流し込みApache CrunchでMapReduceして結果をEntity Metadata StoreとUesr Profile Storeに格納。いわゆるバッチレイヤ。特にEntity(楽曲などのデータ)は、一度生成されたらめったに変わるものではないのでバッチで問題ない、ということらしい。
- Stormにデータを流し込み、Entity Metadata Storeのデータを利用しながらリアルタイムにUesr Profile Storeの内容を更新していく。いわゆるスピードレイヤ。ユーザーの状態は比較的リアルタイムに移り変わっていくのでこういう対応にしていると書いてある。
なぜCassandra?
はあんまり興味がないのでちょろっとだけ。スケーラビリティとジオレプリケーションが主なポイントと書いてある。あとはHDFSとかからのバルクデータロードとかもポイントらしい。
データモデル
ここが一番おもしろかった。ここで利用されているようなデータの特徴として、 - アトリビュート(いわゆるカラム)は自在に増えたり減ったり - クエリされるためにすべてのアトリビュートが必要なわけではない
という特徴がある。行型よりもカラムナ型やドキュメント型のデータベースがマッチしそうな雰囲気。しかし、どちらもすべての要件を満たすわけではない。そこで彼らの考えたスキーマは
こうじゃなくて
CREATE TABLE entitymetadata ( entityid text, feature1 text, feature2 text, feature3 text, -- 続く PRIMARY KEY (entityid, featurekey) ) CREATE TABLE userprofilelatest ( userid text, feature1 text, feature2 text, feature3 text, -- 続く PRIMARY KEY (userid, featurename) )
こういうふうにアトリビュートごとにアイテム(行)を分割するという実装にしたと書いてある。
CREATE TABLE entitymetadata ( entityid text, featurename text, featurevalue text, PRIMARY KEY (entityid, featurekey) ) CREATE TABLE userprofilelatest ( userid text, featurename text, featurevalue text, PRIMARY KEY (userid, featurename) )
で、更に柔軟性を持たせるために、さらにこう改善されていった。
CREATE TABLE entitymetadata ( entityid text, featurename text, featurevalue list<text>, PRIMARY KEY (entityid) )
このモデルはAdRollのDynamoDBでも同じような構成が取られている。以前も紹介したスライドだけど、この20枚目に同じような話が書いてある。
(ADV402) Beating the Speed of Light with Your Infrastructure in AWS | AWS re:Invent 2014 from Amazon Web Services
ということで
直接レコメンデーションやパーソナライゼーションどうこうという話よりは、アーキテクチャやモデリングの話になってしまったけど、このあたりの業界ではLambdaアーキテクチャは当たり前になっているし、さらに拡張しやすい柔軟なモデルもある程度形が固まっているという話をまとめとして終わります。
広告に関するなにか(2015/1/14): Apache Lens at Hadoop meetup
inmobiのレポートシステムでLensを使っているよという話。
Generation 1 : RDBMS
Architecture
- RDBMSで1.5TBくらいのデータを扱っていた。
Challenges
- データロードに24時間近くかかったり3ディメンションくらいしか現実的にはクエリできなかったり・・・いろいろ辛かった。
- 誰もが通る道だよね。でもinmobiもそれやってたって話を聞くとなんか安心するw
Generation 2 : Hadoop + Columnar DB
Architecture
- Hadoop + Columnar DB
- 集計済みのデータ: Columnar DBにいれてダッシュボード利用
- 生に近いデータ: Hadoopにいれてアドホッククエリ。
- Columnar DBに8TB。Hadoopに250TBくらいデータ入れてた。
Challenges
Generation 3 : Apache Lens
Architecture
- Apache Lens使い始めた。
- これを使うと複数のデータソースをOLAPで抽象化できる。しかもマルチディメンションなCUBEっぽく使える。
- メタデータは1箇所で集中管理できる。
- 新しいワークロードに合わせてRedshiftやSpark、Tezも取り入れ始めた。
Generation 4 (Future) : Machine learning workflow in Apache Lens using Apache Spark
をやりたいと思っている。以上。という感じ笑
Apache Lensについて
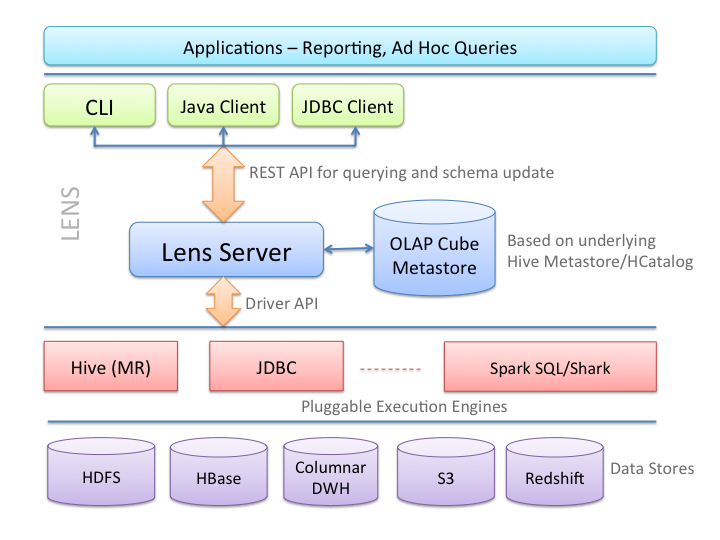
- OLAP Cube QL which is a high level SQL like language to query and describe data sets organized in data cubes.
- A JDBC driver and Java client libraries to issue queries, and a CLI for ad hoc queries.
- Lens application server - a REST server which allows users to query data, make schema changes, scheduling queries and enforcing quota limits on queries.
- Driver based architecture allows plugging in reporting systems like Hive, Columnar data warehouses, Redshift, Impala etc.
- Cost based engine selection - allows optimal use of resources by selecting the best execution engine for a given query based on the query cost. The following diagram shows Lens architecture.
実際のデータストアレイヤを抽象化して、横断的にクエリできるようにしてくれるソフトウェア。という感じだろうか。たぶん、個々のクエリを最適化しなきゃいけないような場面だとつらい気もするけど、アドホックなクエリでいろいろやりたい、という場面にはとても便利そう。
広告に関する何か 2015/1/9
Beating the Speed of Light with Your Infrastructure
(ADV402) Beating the Speed of Light with Your Infrastructure in AWS | AWS re:Invent 2014from Amazon Web Services
AWS Re:Invent 2014でのAdRollの発表のスライド。AdRollと言えばAWSてきにはDynamoDBの事例でよく話題にあがる会社。ちょっと内容をつまみ食いしてみる。
扱っているトラフィックの量
- 150TB/Day
- 5ms以内にレスポンス(サーバー内だけの話のはず)
- グローバルで100万request/sec超え(Dailyでは600億requestsくらいの模様)
- 1兆(!)を超えるアイテム(DBのレコード数だと思う)
アーキテクチャ
アーキテクチャ設計のPrincipleとして下記の2つへの言及がされている。
ひとつめ。
Essentially it means accepting now that in a few years time you'll (hopefully) need to throw away what you're currently building.
-Martin Fowler
ふたつめ。
Ensure your design works if scale changes by 10X or 20X but the right solution for X often not optimal for 100X
-Jeff Dean, Google
どちらも、現実的なところで折り合いを付けましょうというか、ひとつのアーキテクチャを後生大事に引き回すなというか状況に併せてアーキテクチャは作りなおしていこうぜという話。(ざっくり意訳しすぎか)
で、気になるアーキテクチャ。
Biddingは当然データに基いて行われるわけだけど、そのデータ収集から利用までの流れを表したのが下記のフロー図。BatchレイヤとSpeedレイヤ。Lamdaアーキテクチャですかね。
Data Collection(Process) -> Data Storage(Store) -> Global Distribution(Process) -> Bid Storage(Store) -> Bidding(Process) という具合に、ひとつずつの処理にあとにデータストアを置いてチェックポイントをつくることが重要という話が強調されている。 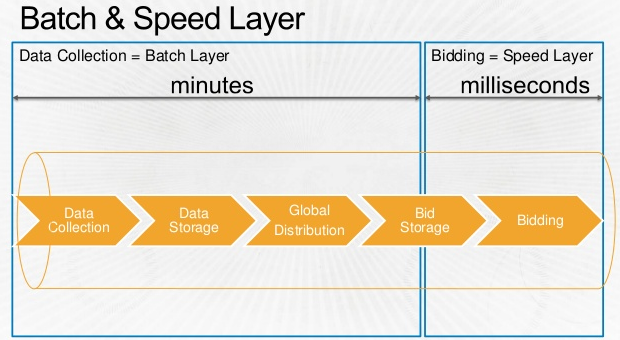 * 冒頭のスライドより抜粋
* 冒頭のスライドより抜粋
こちらはデータ収集部分の話ですね。バッチレイヤ側。トラッキングサーバーで集めたユーザーのログをKinesisとS3に放り込んで、Storm経由で各リージョンのBid Storageに配布している。 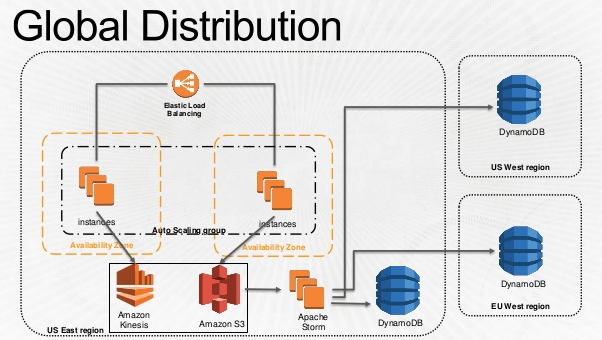 * 冒頭のスライドより抜粋
* 冒頭のスライドより抜粋
ここからは完全に想像だけど、Bidderだけじゃなくてトラッキングサーバーも各リージョンにあると思うので、このグローバルなデータ配布って
Tracker:Bidder=1:n
ではなくて
Tracker:Bidder=n:n
でやっている気がする。グローバルに地理分散しつつ中心のないアーキテクチャ、ということになりそう。かっこいい。
そしてこちらは実際のBidderのアーキテクチャ。超シンプル。 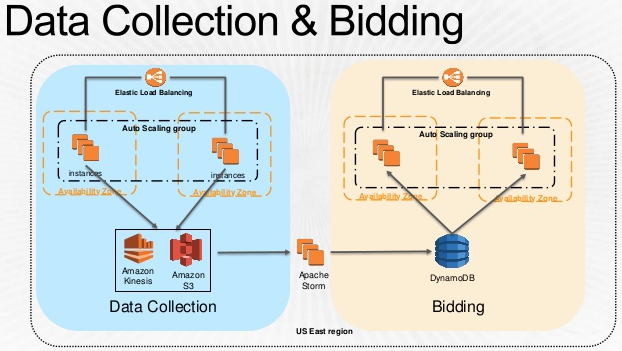 * 冒頭のスライドより抜粋
* 冒頭のスライドより抜粋
Bidderの中身。Erlang使ってるね!TrackerからDynamoDBまで運ばれてきたデータをもとにBiddingしていくわけね。Blackboxというのは、彼ら独自のMachine Learningアプリケーションぽい。 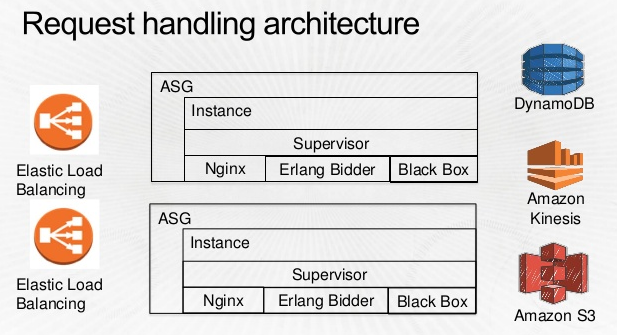 * 冒頭のスライドより抜粋
* 冒頭のスライドより抜粋
DynamoDBに至るまで
DynamoDBの選定経緯みたいなのも語られていたのでまとめてみた。
- Cassandra, Redis, Memcached, HBaseを比べた。
- 最終的にはコスト面でDynamoDBを選択。
- 上記の4つと比較するとDynamoDBは唯一オープンソースではなかった。当然ロックイン問題も考慮した。
- しかしアプリケーションの開発スピードを優先した結果の選択。
まとめ:もっと中身の話が知りたい
AdRollのスライドをざっとまとめてみた。非常にきれいにまとまっていて読みやすかった。でもアーキテクチャだけじゃなくて、もっと中身のアルゴリズムの話とか知りたいよね。でもまあそんなに中身の話を公開している企業があるわけはないので、このへんはKDDの論文とかをあさってみようと思う。で、それをまとめてまたブログに・・・したいんだけど論文は読むのに骨が折れるんだよね・・・
広告に関するなにか 2015/1/7
Could Programmatic Branding Have a Breakthrough Year?
パフォーマンス系、獲得系の広告だけじゃなくてブランディング系の広告においてプログラマティックが利用されるようになっていくのかという話。書いているのがDMPのセールスのひとなのである程度バイアスはかかっているものの、基本に立ち返るいいポスト。
The most fundamental problem with digital branding is that it is truly a one-to-one marketing exercise. If we dream of the “right message, right person, right time,” then matching a user with her devices is table stakes for programmatic branding. How do I know that Sally Smith on desktop is the same as Sally Smith on tablet? Cross-device identity management is the key. Device IDs must be mapped to cookies, other mobile identifiers and Safari browser signals to get a sense of who’s who. Once you unlock user identity, many amazing things become possible.
ということで、ブランディング広告においても"right message, right person, right time"が大事ですと。そしてそれを実現するためにはクロスデバイスなユーザートラッキングが絶対に必要になりますよね。という話。もう一歩話を進めると、以下の3つのAchievementが必要でしょうと。
- Global Frequency Capping
- まずはひとの特定をしたうえで、グローバルなフリークエンシーキャップをかけましょうという話。フリークエンシーキャップって広告主から見ると広告費用の無駄を削ってくれるのでとても大事だと思うんだけど、広告を見るユーザー側からしても、同じ広告との過度な接触を減らすことになるので、ユーザーから見たインターネットの品性を上げてくれるという意味でも大事だと思う。最近、リターゲティングの広告がどこまでもいつまでも追いかけてきて、辟易なことも多いしね。。
- Sequencial Messaging
- で、ユーザーの特定ができてフリークエンシーキャップが掛けられるようになったら、次にストーリーを持って広告を出していきましょうと。カスタマージャーニーという表現も使われている。
- Cross-Channel Attribution
- うえのカスタマージャーニーの話とかぶっている部分も多い気もするが、アトリビューション(分析というよりは、アトリビューションを利用したカスタマージャーニー?)も当然重要ですよねという話。
こんな感じに見てみると、兎にも角にも「クロスデバイスでユーザーをいかにトラッキングしていくのか」がいかに重要かという話が浮き彫りになってくるね。何か論文探してアルゴリズムの話を探してみようっと。。。
ほぼ日刊アドテクニュース 2015/1/6
AppNexus Acquires Cross-Device Technology Leader MediaGlu
AppNexus(the world’s largest independent ad tech companyと紹介されている)が、クロスデバイストラッキングサービスを提供するMediaGluをAppNexusが買収という記事。
どんな技術を使っているんだろうと思ってMediaGluのWebサイト見たけど、
OUR PROPRIETARY ALGORITHM CREATES ACCURATE USER-LEVEL MATCHES USING BILLIONS OF PROGRAMMATIC DATA POINTS AND ADVANCED MACHINE LEARNING.
だって。プロプライエタリ。まあそうだよね。
Through a simple desktop cookie or device ID sync, we can quickly identify mobile and desktop devices which match your 1st or 3rd party data.
となっているので、ユーザーのフットプリントをサーバーサイドに溜めておいて、 機械学習でマッチング して、CookieやデバイスIDをラベルにユーザーを横串さしてあげるのかと。Matching as a Serviceと書いてあるので、API経由で利用できたりしたのかも。お手軽でいいね!(もちろん有料なのだが)
AppNexusは自分たちがこのサービスを使いたいだけではなく、他のプレイヤーがお手軽にクロスデバイスターゲティングできないようにしたかった、というのもあるのかも。
Measure more: improving Estimated Total Conversions with store visit insights
In the coming weeks, we’ll be rolling out store visit measurement to eligible advertisers in the U.S. as the latest enhancement to ETC.
ということでAdWordsの新機能として「店舗への来店予測数をレポートする」ことができるようになるらしい。これを有効化する条件とs知恵
- Have a Google My Business account linked to your AdWords account
- Set up location extensions in your Google My Business account
- Have multiple physical store locations in the US
- Receive a large number of both ad clicks and store visits
とあるので、実績データをもとに、ユーザーの広告クリックなどからコンバージョン(来店)数を予測するという、大枠のしくみとしては比較的単純なことをやっている気がする。
でも、もとデータにもなる、コンバージョンである「来店の実績」ってどうやって取っているんだろう。
DynamoDBを並列処理のためのロックやバッチのチェックポイントに使う
AWS Advent Calander 12/19分。
Kinesis用のFluentdプラグインを書いているので、それについてブログ書きたかったんだけどまだちゃんと公開できるような状態になっていないので、それは冬休みの宿題ということで。
CloudFrontのログを集計して可視化するツールを実装する機会があったので、その仕組みの中で使ったDynamoDBの話や、反省点などを書いてみる。ちなみにs3statというサービスを利用することも考えたんだけど、量的に全然処理できなそう/お金払えばできるけど高そうなので自分で実装することに。
あと、そんなんhive使えばよくね?って話は仰るとおり。もろもろの事情で謎のpythonスクリプトを引き継いでやらなければならなかったのです。
つくったもの
こんな感じの、CloudFrontから出力されるログを最終的に可視化されるまでのパイプライン処理を実装した。

CloudFrontのログの形式
まず、CloudFrontのログは指定したS3バケットに対して下記のような命名規則で集約される。
{ディストリビューション名}_YYYY-MM-DD-HH.{UUID的ななにか}.gz中身はタブ区切りで date, time, x-edge-location, sc-bytes, c-ip, cs-method, .... という感じに、いわゆる普通のアクセスログにキャッシュサービスっぽい項目を足したもの。中にはx-egde-result-typeという項目もあって、これでキャッシュがヒットしたかどうかを追うことができるようになっている。タブ区切りなので非常に扱いやすい。
CloudFrontログのめんどくさいところ
一行一行はタブ区切りなので非常に扱いやすいんだけど、苦労した点がひとつ。エッジロケーションが世界中に沢山あって、それぞれのロケーションの中にエッジサーバーがいっぱいいて、それらがたくさんのファイルを生み出すからということだと思うんだけど、小さなログファイルがたくさん生成されている!今回扱ったディストリビューションでは、1日分で約2万から3万ちかいファイル!しかもひとつひとつは数百キロバイトから数メガバイトなので、HadoopやRedshiftが扱うには小さすぎる。これをある程度のサイズまで集約してあげないと集計処理が難しいわけです。
そこで下の絵のような感じでEC2で一旦S3からデータを取り出して500ファイルずつひとまとめにしつつ軽く一次集計して別のバケットに出力することに。今回はリクエスト数、データ転送量、エッジロケーションごとのリクエスト数くらいしか必要がなかったので、無駄なデータの排除もここでやることに。(掃除&集計しちゃうので結局ファイルサイズは大きくならないんだけど、ファイル数は劇的に減っているのでまあいいかなと。それにファイルサイズを大きくするのではなくて処理を効率化することが目的なので)

ファイルの集約&一次集計を並列化する
逐次生成されてくるファイルを15分や1時間ごとに端から処理していく、ということであればこれでOKなんだけど、今回はまず2〜3週間まえから発生しているデータを先に取り込んで、それから逐次処理をしていく必要があった。最初に取り込まなきゃいけないデータが大量すぎてシングルスレッドだと現実的な時間じゃおわらないので並列化することに。S3のオブジェクト名をキーにDynamoDBにロックテーブルを作ることで並列化を実現。

こんな感じにDynamoDBのレコードをロックファイルのように使うことでS3上の同じファイルを重複処理してしまうのを防ぐ。こうすれば大量のプロセスを立ち上げて同時に処理を始めても重複処理を避けられる。DynamoDBにはConditional Writeという機能があって、例えば「指定したキーのレコードが存在しなければ書き込む」というようなことができるので実装は非常に楽。書き込みリクエストが失敗したらロックされていた、成功したら自分がロックできた、というような分岐を書けばOK。テーブルの構造はこの絵のとおり、アトリビュートを何も持たない、ハッシュキーだけのテーブル。
一次集計済みのデータをRedshiftに突っ込む
次にデータをRedshiftに投入する。Redshiftへの重複ロードを防ぐところでも同じようにDynamoDBをロックテーブルとして使った。やってることは同じなんだけど、こっちは意味合い的には「これはやった」とか「ここまでやったよ」というようなチェックポイント的な意味合いで使ってます。こんな感じ。

JaspersoftでRedshiftのデータをレポート化する
ここはうまい絵がないのであれなんだけど、RedshiftとJaspersoftの体験版を組み合わせてみた。非常に簡単に設定できていい感じだった。このあたりはまた今後ちゃんと絵を揃えから書くお。
うまくいったこと
バッチ処理の冪等性の確保。もともと「なんど流しても副作用が(できるだけ)発生しない」処理にしたいというところからDynamoDBの利用を決めた。これがあるおかげで、何度流しても重複処理がされない。おかげで何かしらの問題が起きた時の再処理というか続きから処理をするという実装が非常にやりやすくなった。
反省点
Data Pipeline使えばよかった。いまこのパイプラインは1時間に1回のcronで動いている。あまりにも時間がなくてData Pipelineを覚えながらやる余裕がなかったのでこんな感じになってしまったけど、あれを使うと、スケジュール管理を外部化できるというのが大きい。1時間に1回EC2を起動してリポジトリからスクリプトを落としてきて実行する。そしてそのスケジュール管理はData Pipeline、みたいな感じにできると、非常に処理の可視性というかコントロール性が高くなっていいんじゃないかなぁと思った。
以上。