広告に関するなにか(2015/1/14): Apache Lens at Hadoop meetup
inmobiのレポートシステムでLensを使っているよという話。
Generation 1 : RDBMS
Architecture
- RDBMSで1.5TBくらいのデータを扱っていた。
Challenges
- データロードに24時間近くかかったり3ディメンションくらいしか現実的にはクエリできなかったり・・・いろいろ辛かった。
- 誰もが通る道だよね。でもinmobiもそれやってたって話を聞くとなんか安心するw
Generation 2 : Hadoop + Columnar DB
Architecture
- Hadoop + Columnar DB
- 集計済みのデータ: Columnar DBにいれてダッシュボード利用
- 生に近いデータ: Hadoopにいれてアドホッククエリ。
- Columnar DBに8TB。Hadoopに250TBくらいデータ入れてた。
Challenges
Generation 3 : Apache Lens
Architecture
- Apache Lens使い始めた。
- これを使うと複数のデータソースをOLAPで抽象化できる。しかもマルチディメンションなCUBEっぽく使える。
- メタデータは1箇所で集中管理できる。
- 新しいワークロードに合わせてRedshiftやSpark、Tezも取り入れ始めた。
Generation 4 (Future) : Machine learning workflow in Apache Lens using Apache Spark
をやりたいと思っている。以上。という感じ笑
Apache Lensについて
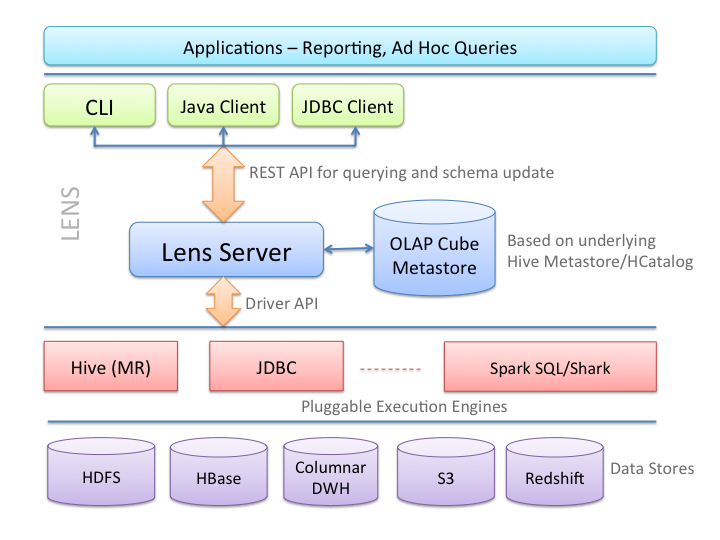
- OLAP Cube QL which is a high level SQL like language to query and describe data sets organized in data cubes.
- A JDBC driver and Java client libraries to issue queries, and a CLI for ad hoc queries.
- Lens application server - a REST server which allows users to query data, make schema changes, scheduling queries and enforcing quota limits on queries.
- Driver based architecture allows plugging in reporting systems like Hive, Columnar data warehouses, Redshift, Impala etc.
- Cost based engine selection - allows optimal use of resources by selecting the best execution engine for a given query based on the query cost. The following diagram shows Lens architecture.
実際のデータストアレイヤを抽象化して、横断的にクエリできるようにしてくれるソフトウェア。という感じだろうか。たぶん、個々のクエリを最適化しなきゃいけないような場面だとつらい気もするけど、アドホックなクエリでいろいろやりたい、という場面にはとても便利そう。