広告に関する何か 2015/1/9
Beating the Speed of Light with Your Infrastructure
(ADV402) Beating the Speed of Light with Your Infrastructure in AWS | AWS re:Invent 2014from Amazon Web Services
AWS Re:Invent 2014でのAdRollの発表のスライド。AdRollと言えばAWSてきにはDynamoDBの事例でよく話題にあがる会社。ちょっと内容をつまみ食いしてみる。
扱っているトラフィックの量
- 150TB/Day
- 5ms以内にレスポンス(サーバー内だけの話のはず)
- グローバルで100万request/sec超え(Dailyでは600億requestsくらいの模様)
- 1兆(!)を超えるアイテム(DBのレコード数だと思う)
アーキテクチャ
アーキテクチャ設計のPrincipleとして下記の2つへの言及がされている。
ひとつめ。
Essentially it means accepting now that in a few years time you'll (hopefully) need to throw away what you're currently building.
-Martin Fowler
ふたつめ。
Ensure your design works if scale changes by 10X or 20X but the right solution for X often not optimal for 100X
-Jeff Dean, Google
どちらも、現実的なところで折り合いを付けましょうというか、ひとつのアーキテクチャを後生大事に引き回すなというか状況に併せてアーキテクチャは作りなおしていこうぜという話。(ざっくり意訳しすぎか)
で、気になるアーキテクチャ。
Biddingは当然データに基いて行われるわけだけど、そのデータ収集から利用までの流れを表したのが下記のフロー図。BatchレイヤとSpeedレイヤ。Lamdaアーキテクチャですかね。
Data Collection(Process) -> Data Storage(Store) -> Global Distribution(Process) -> Bid Storage(Store) -> Bidding(Process) という具合に、ひとつずつの処理にあとにデータストアを置いてチェックポイントをつくることが重要という話が強調されている。 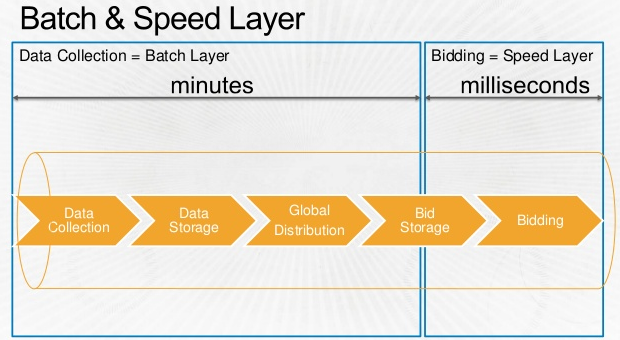 * 冒頭のスライドより抜粋
* 冒頭のスライドより抜粋
こちらはデータ収集部分の話ですね。バッチレイヤ側。トラッキングサーバーで集めたユーザーのログをKinesisとS3に放り込んで、Storm経由で各リージョンのBid Storageに配布している。 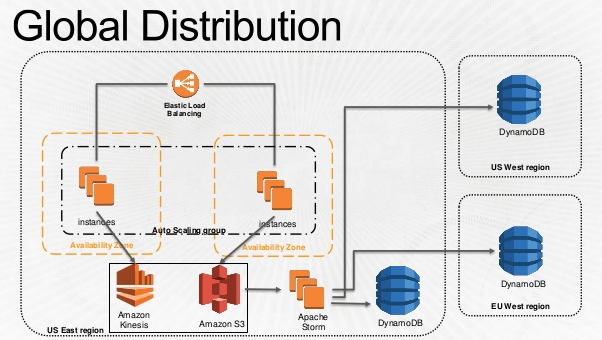 * 冒頭のスライドより抜粋
* 冒頭のスライドより抜粋
ここからは完全に想像だけど、Bidderだけじゃなくてトラッキングサーバーも各リージョンにあると思うので、このグローバルなデータ配布って
Tracker:Bidder=1:n
ではなくて
Tracker:Bidder=n:n
でやっている気がする。グローバルに地理分散しつつ中心のないアーキテクチャ、ということになりそう。かっこいい。
そしてこちらは実際のBidderのアーキテクチャ。超シンプル。 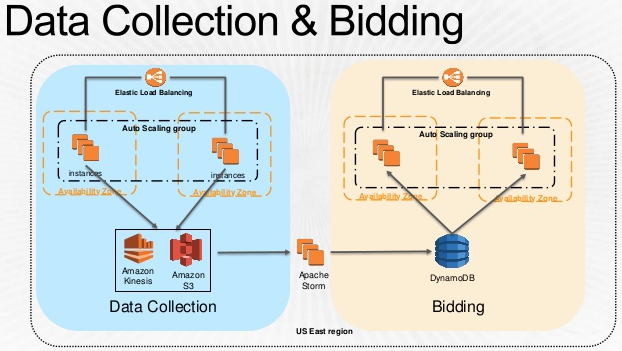 * 冒頭のスライドより抜粋
* 冒頭のスライドより抜粋
Bidderの中身。Erlang使ってるね!TrackerからDynamoDBまで運ばれてきたデータをもとにBiddingしていくわけね。Blackboxというのは、彼ら独自のMachine Learningアプリケーションぽい。 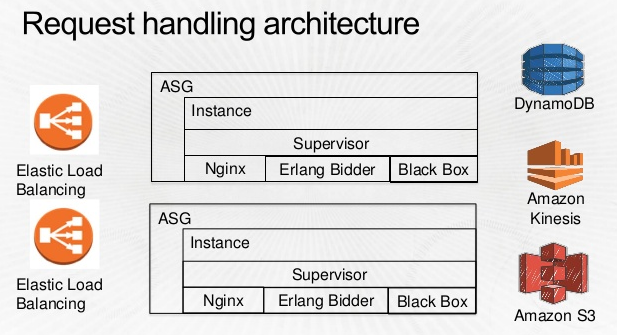 * 冒頭のスライドより抜粋
* 冒頭のスライドより抜粋
DynamoDBに至るまで
DynamoDBの選定経緯みたいなのも語られていたのでまとめてみた。
- Cassandra, Redis, Memcached, HBaseを比べた。
- 最終的にはコスト面でDynamoDBを選択。
- 上記の4つと比較するとDynamoDBは唯一オープンソースではなかった。当然ロックイン問題も考慮した。
- しかしアプリケーションの開発スピードを優先した結果の選択。
まとめ:もっと中身の話が知りたい
AdRollのスライドをざっとまとめてみた。非常にきれいにまとまっていて読みやすかった。でもアーキテクチャだけじゃなくて、もっと中身のアルゴリズムの話とか知りたいよね。でもまあそんなに中身の話を公開している企業があるわけはないので、このへんはKDDの論文とかをあさってみようと思う。で、それをまとめてまたブログに・・・したいんだけど論文は読むのに骨が折れるんだよね・・・