SORACOM JunctionとeBPFでパケットキャプチャしてISPのようにトラフィック分析しよう(立志編)
今日はeBPFについて書いてみようと思います。
いくつかのDisclaimar
- これはSORACOM Adevent Calendar 2023の記事です
- わたしはこの記事の執筆現在、株式会社ソラコムで働いていますが、このブログ記事は会社を代表する意見やコメントではありません。いちユーザーとしてこんな感じのことをSORACOM使ってやってみようぜという記事です。
この記事はSORACOM JunctionとeBPF使うと、まるでISPのように、自分が管理するSIMトラフィック解析ができるよ!とドヤ顔で話すための試行錯誤とその失敗(いまのところ)の軌跡です。
eBPFってなに?
さて本題に戻ります。みなさま、eBPFってご存知ですか?eBPFとはカーネルの様々なイベント(例えばSyscall、カーネル内の関数が呼び出されたとき、パケットがNICに到達したとき)にフックして、任意のバイトコードを実行できるサンドボックスです。Kernelを直接変更したり、Kernelモジュールを書いたりすることなく、安全にKernelを拡張することができることが特徴です。代表的な事例としてはトレーシングやロードバランサー、DDoS Mitigationなどがあげられます。
例えばCloudflareはエッジサーバー内において、DDoS対策のためにルーターから届く毎秒2000万のパケットから意味のある10万のパケットのみをフィルタしてアプリケーションに届ける、というパイプラインを構築しています。毎秒2000万ですよ?すごくないですか?
なんでこんなに速度が出るかというと、カーネル内で任意のコードを(安全に)動かせるため、ユーザーランドへのメモリコピーやコンテキストスイッチングを避けることができます。また、例えばXDPというフックポイントを利用するとOSのネットワークスタックより前に処理を差し込めたり、NIC内でその処理を実行したりすることもできてしまいます。
下の画像はXDPとOSのネットワークスタックについての関係性について説明している図で、XDPのフックポイント(XDP eBPF)が左下のパケット到着直後に存在しているのが見て取れると思います。例えばここでeBPFプログラム内でXDP_DROPという結果を返すと、このタイミングでパケットを捨てることができてしまうのです。すごくないですか?

画像出典: Express Data Path - Wikipedia
Cloudflareがそれをどうやって活用しているかについては下記のスライドとブログを読んでいただくとどんなことをやっているのか、またそれをどうやって実装しているのかというのがイメージ湧くと思います。とてもおもしろいのでぜひ。
わたしとeBPF
わたしがeBPFに興味を持ったのは、SORACOMでのトラフィック分析、より具体的に言えばゼロレーティングのためのトラフィック分析に利用できないか?というのがきっかけです。
ゼロレーティングとは、例えば「このSIMは月額980円でxxGB利用可能です!しかもLINEでの通信利用分は無料!」というアレです。アレを実現するためには、自分が管理するトラフィックについて、どことどのくらいの量の通信をしたのか、ということを把握できる必要があります。
SORACOMには、SORACOM Junctionというサービスがあり、自分のアカウント内のすべてのSIMの通信をミラーして任意の宛先に送信することができます。それを受け取って解析、一番シンプルには宛先ドメインごとに通信量集計をすればゼロレーティングが実現できそうですよね!
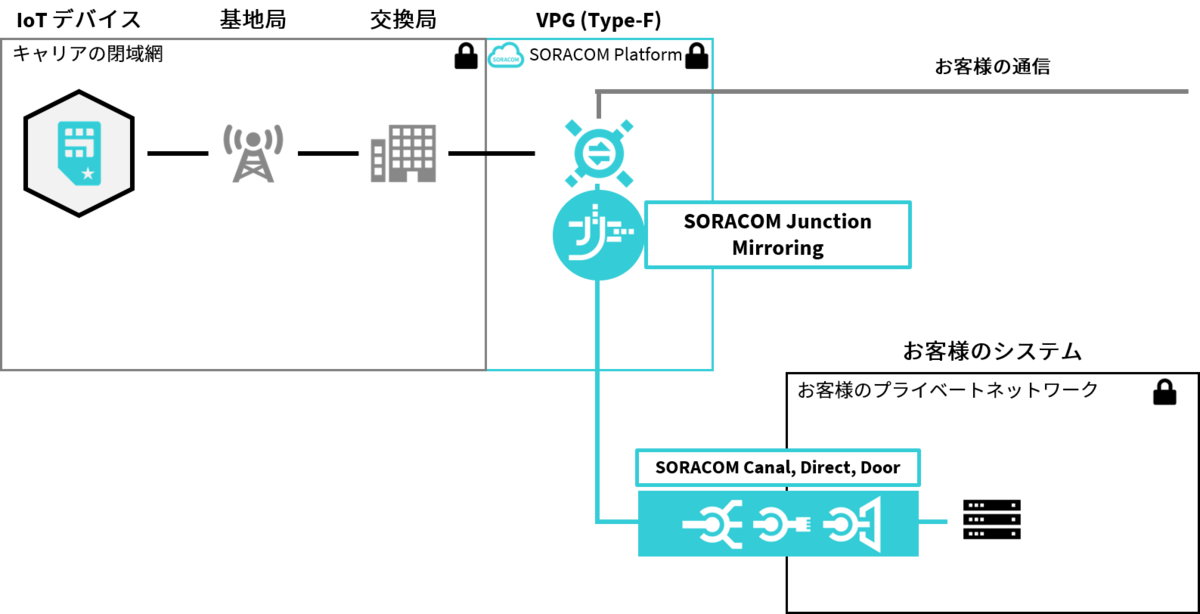
画像出典 - SORACOM Junction - SORACOM
ゼロレーティングとかDPI(Deep Packet Inspection)と呼ばれるような技術分野は、少なくとも私が知る限りはまだまだプロプライエタリな製品を使う以外の選択肢がなく、自分で実装したりするような事例というのは少ないのかなと思っています。そういう背景もあって、普段から「ゼロレーティング、自分で実装できたらかっこいいよな。ひとつのチャレンジテーマとして持っておこう」と思っていました。
そんななか、たまたまRustの勉強をしているときに下記の本を読んでいる中で出会った「Rustでパケットキャプチャ」という章において、Rustを使えばSocket APIよりも低レイヤなIPパケットが簡単に扱えることを知りました(すいません、ネットワークプロバイダのSORACOMのSAとしてそんなことも知らなかったのかよ、というツッコミは甘んじて受けます)。この本の第2章はpnetというクレートを使って、データリンク層から取り出したフレームを扱うという演習になっています。
そして、Rustのpnetで遊んでいるうちに「よりパフォーマンスを出すパケットキャプチャプログラムを書くにはどうすればいいだろう?」としらべているなかで出会ったのがeBPFだったというわけです。当時Rustを触っていたということもあり、AYAというRust向けeBPFライブラリを使ってeBPFでパケットキャプチャをやってみたという話をSORACOM UGで発表したりしました。(ほんとうちょっと触っただけ)
やってみた - SORACOM Junction + eBPF + BCCでパケットキャプチャ
今回あらためて、BCCというツールセットと、PythonとCを使って以下のようなデモプログラムを実装してみました。パケットはもちろんSORACOM Junctionでミラーリングした実際の自分のSIMの通信を利用します。全体像としてはこんなかんじ。

パケットを受け取るEC2の中はこんな感じになりました。

前回SORACOM UGで発表した時点ではAYAを使っていましたが、より情報の多いBCCのほうが書きやすかったとうこともあり、今回はこちらを使いました。
BCCとは、eBPFプログラムを実装、実行するためのツール群でこれを使うとPythonやluaでフロントエンド(ユーザーランドプログラム)を書けるようになります。例えば、eth0で受け取ったパケットをXDPのところですべて破棄するプログラムは以下のように書けます。これなら「おれも書けるな」という気持ちになりませんか?

現状と今後
ということで書き始めるところまではたどり着いたんですが、このブログを書いている朝まで動いていたでもプログラムが「何もしていないのに壊れてしまった」のです・・・本当はInfluxdbやAmazon Timestreamに入れたところのデモ画面くらいまでたどり着きたかったのですが・・・XDPにプログラムをアタッチするところがどうやらうまくいかなくなってしまって、いまはlibbpfやBCCそのもののコードをちょっと調べているところです。より低レイヤな部分を覗くせっかくの機会だと思って。。笑
ということで実際の動いているデモは冬休みの宿題としてまた新たにブログ記事にまとめられたらと思います。
SORACOM JunctionとeBPF使うと、まるでISPのようにトラフィック解析ができるよ!とドヤ顔で言えるようになる日までもう少しがんばります。
セルラーモデムの謎を追う その1 :導入編
みなさん、こういうデバイス使ってIoTしたことありますか?
これはUSBドングルタイプのセルラーモデムで、例えばラズパイやPC、Macに接続することでそれらのコンピューターにセルラー通信上でのIP通信を実現可能にしてくれます。使ったことある方はわかると思うんですが、このデバイスはpppインターフェイスとしてOSに認識されます。が、実はSORACOMはppp方式での接続を提供していません。このことは下記のドキュメントのPDP Typeが「IP」となっていることからわかります。PDP Typeとはパケット接続の認証方式のことで、IPもしくはPPPという2つの方式があり、SORACOMはIP方式のみを採用しています。他の多くのキャリアも同様です。

となると、え?なんでpppインターフェイスが見えるの?となりますよね。疑問に思ったことありませんか?別に気にしなくても使えるんですが。
これについてはIIJの方が下記のブログ記事で解説してくださっていますが、実はppp通信しているのはOSとモデムの間だけだということがわかります。しかし、なぜこんな方式になっているのでしょうか?とか気になっちゃいますよね。
他にも・・・ATコマンドでセルラーモデムを扱ったことあるひとはわかると思うんですが、モデムをラズパイに接続するとシリアルデバイスとして認識され、screenやcuコマンドを使ってASCIIベースの対話型インターフェイスを介してコマンドのやり取りができる状態で立ち上がってきます。ちなみにATコマンドってなに?って人はこちらのブログを読んでみてください。ざっくりいえば「モデムを制御したり情報を取得したりするためのもの」であり、IoTデバイスの入門書やキットでもよく「ATコマンドでセルラー通信をしてみましょう」というコーナーを見かけます。
でもここで、実際のIP通信の際にはOSはどうやってモデムを扱ってるの?まさかATコマンド?みたいな疑問が湧いてきませんか?
これについてはLinux Documenation Projectのガイドによれば以下のような記載があります。ざっくり言えば「モデムはAT-commandモードとして起動し、ATDコマンドが発行されたタイミングからon-line dataモードと呼ばれる土管モードに入る」ということですね。
When the modem is first turned on it's in the command mode (also called terminal mode, idle state or AT-command mode). Anything sent to it from the PC is assumed to be an AT command and not data. Then if a dial command is sent to it (ATD...), it dials and connects to another modem. It's now in the on-line data mode (connected) and sends and receives data (such as Internet pages). In this mode, any AT command one trys to send it will not work but will be transmitted to the other modem instead. Except for the escape command. This is +++ with a minimum time delay both at the start and end. The time delay allows the modem to determine that it is likely a real escape and not just +++ in a file being transmitted.
ここまでわかってきたことを総合していくとLinuxやMacのようなOSたちは、モデムをon-line dataモードにしたうえでシリアルデバイスとして取り扱い、さらにそのうえにpppインターフェイスを作成し、自身のもつ通信スタックを用いて通信を行っているであろうことが想像できます。このブログでは「LinuxやMacでセルラーモデムを使ってIP通信が実現されている仕組み」の詳細にDive Deepしていきたいと思います。
ちなみにですが、ArduinoにはTinyGSMという著名なセルラー通信ライブラリがあります。
これを利用するとさまざまな通信モジュールにおいて非常に簡潔なコードでHTTP通信やMQTT通信が実現可能です。これも前述のLinuxやMacのように様々なモジュールを使って柔軟な通信を実現してくれるという意味ではとても似て見えるのですが(役割としてはとても良く似ている)、実は全く違う仕組みです。このライブラリは通信モジュールが持っている、通信用のATコマンドを利用して通信をする仕組みになっています。例えばQUECTELのモジュールはAT+QISENDというTCPでのデータ送信コマンドや、さらにはAT+QHTTPGET、AT+QHTTPPOSTといった高位の通信を行うためのコマンドも備えておりこれらを活用しています。つまり、TinyGSMの場合はモデム自身が持っている通信スタックを使っており、モデムとMCUはATコマンドでやりとりしている、ということになります。
次回以降は実際にいろいろ触ってみながらやっていきたいなと思います。最終的には自作のTCPスタックでモデムを使って通信、みたいなところまで行けたら最高だなと思いますが、さてどこまでいけるだろうか・・・
お楽しみに!
SORACOMで構成できるネットワークとNAT越えのさまざま
この記事では、SORACOM Air for セルラーやSORACOM Arcで接続されたデバイスとクラウドアプリケーションの間の通信について考えてみます。
なお、わたしはこれを書いている2021/12/16現在、株式会社ソラコムで働いていますが、この記事内に出てくるソラコムの仕様についてはすべて外部から観測可能な話に基づいて書いています(のはず)。
ちなみにこの記事は株式会社ソラコム Advent Calendar 2021の19日目の記事です。
デバイスとクラウドの通信にはどんなものがある?
IoTアプリケーションにおける通信のユースケースとしては以下のようなものがあげられます。また、これらを組み合わせたアプリケーションも考えられるでしょう。
テレメトリ
デバイスからクラウドに対してデータを送信する。スマートメーターのように数時間おきから数日おきに長いインターバルで定期送信するもの、ロボットの位置情報やステータスのように連続的に送信するもの、漏電監視装置のようにイベントドリブンで送信するものなど、流速や通信頻度は様々。情報の向きでいうとアップリンクです。
リモートアクセス
クラウドからデバイスに対してアクセスするパターンです。メンテナンスのためのSSHやリモートデスクトップ、コマンドの発行などシグナリング的なものもこのユースケースに入ってきます。このユースケースは主体がクラウドアプリであり、クラウド(もしくはその向こう側にいるユーザー)のタイミングでデバイスにアクセスできる必要があり、ネットワーク的にはこれの実現方法がもっとも複雑になりがちです。(乱暴ではありますが)情報の向きで言うとダウンリンクです。
では、これらの通信が、SORACOMのネットワーク内で実際どのように実現されるか見ていきましょう。
SORACOM Air for セルラー/SORACOM Arcのネットワーク構成

まず、SORACOM AirのSIMを挿したりSORACOM Arcでそのまま通信すると、上のようなイメージで外部と通信することになります。ポイントはデバイスにはプライベートIPアドレスがアサインされること、インターネットとの通信の際にNATされることというところでしょうか。
テレメトリのようにデバイスからインターネットに向けた通信(と、TCPの場合そのもどり)についてはなんの問題もないですね。逆に、リモートアクセスのほうは、どうやってNATを越えるかというのが議論になってきますね。中身の話をするまえにSORACOMの取りうる構成をもう少し見ていきます。
VPGを利用した場合に取りうる構成
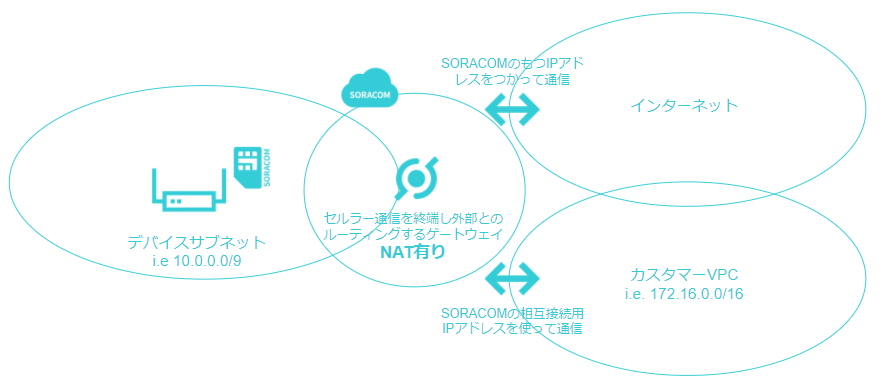
SORACOMにはSORACOM CanalやSORACOM Door、SORACOM Directと呼ばれる、外部ネットワークとプライベート接続するためのサービスがあります。上記の絵はSORACOM Canalを使って利用者のVPCとピアリングをした際のイメージです。VPCとの通信の際にもNATされることに注意してください。
つまりクラウドからデバイスのIPアドレスは見えない
このNATを挟む構成のため、クラウド側からソケットを開いて通信をすることはできません。ここでリモートアクセスに関してNAT越えの工夫が必要になってきます。
なお、こういう書き方すると「NATしないほうが便利じゃん」という見え方をするかもですが、この構成になっていることでデバイスは「デフォルトで外部からアクセスできない」というsecurity by defaultになっていることをお忘れなく!
でも、クラウドからデバイスにデータ送信したいよ!
もちろんです。わかります。以下のような方法が考えられます。
方法1: デバイスからポーリング
例えばデバイスから1時間に1回、クラウドにHTTP Getリクエストを送信して、そのレスポンスで必要な情報を渡すという方式です。もちろん、HTTP Postによるテレメトリの送信のレスポンスに、という形であわせ技にしてもよいでしょう。
クラウド側の実装としてはデバイスIDでルックアップ可能な「あるべき姿」テーブルを保持しておく形になりますね。AWS IoT Coreの「デバイスシャドウ」と同じコンセプトです。
SORACOMの機能としてはメタデータサービスを活用することだけでこれが可能になります。デバイスから、取得済みの情報のバージョンやタイムスタンプを再度、メタデータ側に返させるようにしておくと、どこまでデータが同期されているかも管理できるようになりますね。
それ以外のやり方としてはSORACOM BeamやSORACOM Funkを使うというやり方が考えられます。前者はSORACOM内部に配備されるリバースプロキシ、後者は同じくSORACOM内部に配備されるAWS Lambda等FaaSへのエントリポイントといった体のサービスたちです。
もちろん、外部サービスにデバイスから直接アクセスしにいってもらうのもOKなんですが、この場合デバイスをどうやって認証するのかというのが課題になってきます。SORACOM BeamやSORACOM Funkは、デバイスからのポーリングリクエストをSORACOM内で終端します。その際、回線情報をベースに端末を識別することができますので(これをもちろんアプリケーションで利用可能です)
これ、アナログなように見えますがIoTデバイス(とくにバッテリー駆動のもの)ではいちばんいい戦略だと思います。なぜなら、通信のタイミングをデバイス側で完全にコントロールできるので、それ以外の時間帯、モデムをスリープさせておくなどができるからです。
なお、SORACOMではこれをデバイスリードパターンと呼んでいます。
方法論2: TCPソケット、WebSocket、MQTT、WebRTCなど(いろいろレイヤは違うけど)プロトコル自体にNAT越えの能力が備わっている通信方式を使う
TCPのraw socketとかWebSocketとかMQTTとか話が散らかってるのでそれぞれ個別に解説してみます。
TCPソケット
ソケットプログラミング、お好きですか?(わたしは好きです)
デバイスからクラウドアプリケーション上のエンドポイントに対してTCPセッションを確立し、それをソケットとして利用することによってデバイスから、クラウドからどちらからの通信も可能になります。昔からある手法ですが、実際いまも有効活用されている手法ですね。
ただ、もしいまから新しくアプリケーションの設計をするのであればこの方法はあまりおすすめしません。なぜなら、あまりにも「生」だから、といったらいいでしょうか。例えばメッセージの電文フォーマットの定義(STXとETXを使うとかみたいなところ。JSONでやろうとかそのもっと前段)を決めなければいけなかったり、セッション切断時の復旧方法なども自分で決めて実装をしていかなければなりません。既存の仕組みを利用しなければいけないようなケースでない限り、後述のプロトコルをつかったほうがよいでしょう。
WebSocket
これも比較的低レイヤなプロトコルなのと、Webとついてるくらいなのでブラウザ環境があるならこれを選ぶのもありかなと思うのですが、その前提をもたないIoT向けデバイスの場合、わざわざWebSocketを使わなくてもいいかなという気がします。選ぶべき場面としては、(厳密にはWebSocketとイコールではありませんが)socket.ioベースのサービスに接続したい、といったようなときでしょうか。
MQTT
IoTといえばMQTT。なぜなら軽量だから!
といった謳い文句を聞いたことがある方も多いと思います。そして、その宣伝ぽさや受け売り感に若干うんざりしてる方も多いかもしれません。ただ、わたしもIoT向けのメッセージングベースの双方向プロトコルという観点で言えば、MQTTがいちばん無難かなと思います。理由としては軽量だからAWS IoT CoreやGoogle IoT Coreなど、マネージドサービスとして提供されているMQTTブローカーの選択肢が豊富だからというところになります。また、TCPソケットやWebSocket(最近ぜんぜん触ってないのであんまりキャッチアップできてないですが)よりも高レイヤなプロトコルであり、メッセージのQoSやコネクションの維持(キープアライブや復旧)に関しての取り決め、そしてそれらの実装がそろっていることなども挙げられます。
なお、AWS IoT CoreやGoogle IoT CoreはMQTTブローカーを提供しますが、MQTTの機能だけを提供するものではなくMQTTをトランスポートレイヤに利用する、メッセージングやデバイス管理のためのサービス群と捉えるのが正しいかなと思います。つまり、生のMQTTクライアントで接続するだけだとその恩恵の一部しか享受できないのでご注意ください。これらのサービスを使うのであれば各プロバイダが提供しているSDKを利用するのがおすすめです。
なんていう話をして舌の根も乾いてないところですが、実際にはAWS IoT CoreをMQTTブローカーとして使えればいいというケースも多くあると思います。実際、AWS IoT Coreってマネージドで可用性高くて、どこからでもセキュアにメッセージをPublishしたりできるし、ConsumerとしてLambdaをぶら下げたりできる、ひじょーーーうに優秀なMQTTをブローカーですよね。SORACOMの場合、SORACOM Beamを使うと簡単かつセキュアにAWS IoT Coreにデバイスを接続できますよ!
WebRTC
すごい強引ですがここでWebRTCも。というかこの記事、本当はUDPのNAT越えについて書きたかった(だけ)なんですが、DeNAさんのアドベントカレンダーでゲームでよくある「NATタイプ」はどう判定しているの?という素晴らしい記事が公開されているので、少し話をずらした結果がこの記事なんですw
WebRTCは主に音声や映像のP2P転送のための技術(文脈によってはサービス)として注目されていますが、ほかにもデータチャネルというメッセージ送受信のための仕組みもその仕様の中に含まれています。
ちなみに、SORACOM Air for セルラー上でWebRTCを使った映像の送信については2年前のSORACOMアドベントカレンダーで、WebRTCでロボット操縦しようぜ!というタイトルでAmazon Kinesis Video Steamを使って試してみています。なお、SORACOM Air for セルラーはSTUNによる通信はできず、TURNが利用されていました(つまりAddress Dependant NATもしくはAddress And Port Dependant NATを利用している)。
また上記の記事内にて言及がありますが、Amazon Kinesis Video StreamsのサービスにはSTUNとTURNも含まれていますので、MQTTと同じ用にマネージドなブローカーが出揃ってきているという状況になっていることも言及しておきます。
(ググっていたら見つけた、ejabberdの会社が開発をリードしているerlangで書かれたstun/turn、余裕があればコードリーディングしようと思っていましたがちょっと時間切れなのでまた今度)
方法論2についてのまとめ:
いろいろ紹介してきましたが、いまのところプロトコルの理解の容易さとマネージドサービスを介して利用できること、またSDKやライブラリの出揃い具合の観点からMQTTが一番扱いやすいと言えると思います。
方法論3: IPレイヤで双方向にルーティング可能にする
これ、見た目上シンプルに映ることも多いのですが、実際にはいちばん面倒です。
IPレイヤでルーティング: L2
今回の例ではカスタマーVPCの中にEC2があって、そこからデバイスに対して通信をしたいとしましょう。NATがあるのでそのままでは直接通信はできません。

ここでSORACOM Gateというサービスが登場してきます。このサービスはオーバーレイネットワークを使ってデバイスサブネットをEC2のところまで延伸してくれます。絵にするとこんな感じです。SORACOM内に配備されているゲートウェイ(これをVPG、Virutal Private Gatewayと呼んでいます)からEC2までVXLANというプロトコルをトンネルとして使ってオーバーレイネットワークを作っています。(IPSecによるVPNに似てるとお考えいただいても大丈夫です)

なお、Gate Peerを冗長化するために下記のようにGate Peerを複数デプロイすることができます。アプリケーションレイヤの冗長化であればこれらをDNSラウンドロビンしてやるのが手っ取り早いでしょう(それでOKなアプリケーションプロトコルを利用していれば)。ネットワークレイヤでやるのであれば、VRRP over VXLANなんてのもありかもしれません(いまぱっと考えて思いついただけですが、生のEC2ネットワークではなく、VXLAN内なのでVRRPいけるかも、と思ってます。あとで試してみよう。)

また、すでに古文書の領域になりつつあるAWSデザインパターン(ほめてる)にあるFloating IP Addressデザインパターンも利用可能です。下記のイメージで、仮想IFを別ホストにハンドオーバーする感じです。具体的な手順としては、1. 仮想IFのダウンを検知 2. SORACOMのAPIを使って既存仮想IFをホストしているGate Peerを削除 3. 新しいGate Peerを登録 4. 新しいGate Peer上でVXLANトンネルを作成、という形です。Active/Standby方式なので多少のダウンタイムは発生しますが、確実に冗長性を確保できるひとつの方法です。

さて、ここまでお読み頂いていてお気づきの方もいらっしゃるかも知れませんが、Gate Peerはデバイスサブネット内に配置されているので同一L2ネットワーク内での通信をしています。既存のネットワークと接続する場合、このGate Peerをルーター的に利用して、その向こう側にあるサーバーたちと通信させたくなります・・・よね?
実はこれには技術的なハードルがあります。これについては次のパートで解説します。
IPレイヤでルーティング: L3
L3でのルーティングとは、言い換えるとNATなしで外部ネットワークと通信したい、ということだと捉えてもらえればと思います。(伝わるかは自信ありませんが・・・)絵にすると以下のようなイメージです。強い意志をもってNATを乗り越えるのです!

技術的なハードルについてはこちらのSORACOM公式ブログのポスト「SORACOMで拡張する企業ネットワークの構築例」 に解説がありますので、そちらを併せて呼んでみていただければと思いますが、デバイスから送信されたパケットは一旦必ずSORACOMのゲートウェイ(VPG)に吸い込まれます。ここで宛先がデバイスサブネットローカル(この例では10.0.0.0/9)だった場合のみそのままL2のままフォワーディングされますが、それ以外の宛先の場合L3でルーティングされます。以下のような感じ。

この制約をうまく解決してくれるのがSORACOM Junctionのリダイレクションです。この機能は、予め設定した転送先のIPアドレスに対して「すべての」パケットを「フォワード」してくれます。すべての、ということはインターネット向きのパケットも対象になることに注意しましょう。またL2でのフォワードであって、L3でのルーティングではありませんので、フォワード先に指定できるのはあくまでデバイスサブネットの空間内のIPアドレスに対して、ということになります。今回の場合、下記のようにSORACOM GateのGate Peer(10.0.0.100)にフォワード先を設定することによって、ついに念願のNATなしのルーティングが実現しました!

なお、この構成を冗長化するには、先程のFloating IP Addressデザインパターンを使うのがよいでしょう。Gate Peerをハンドオーバーする際、SORACOM Junctionのフォワード先の設定も一緒に変えてやるかんじです。
方法論3についてのまとめ
と、こんなかんじにIPレイヤで冗長性をもったルーティング構成を構築することもできるようになっています。
まとめと所感
ということでSORACOMで取りうるアプリケーションとデバイスを接続するためのネットワーク構成のパターンを思いつくまま(たぶんだいたい網羅してる)に紹介してきました。
じゃあどう選べばいいのよ?という声が聞こえてきそうですがわたしの意見としては、IoTの文脈においては可能な限りデバイスから生成したソケットのなかで双方向通信を行うHTTPポーリングやMQTTを使うべきと考えます。理由は2点
- ネットワークインフラのレイヤでIPリーチャビリティ(今回の方法論3)を確保しようとすると、まさに「インフラ」をマネージする必要が出てくること。費用面だけでなくて、運用の手間も増える。
- クラウド側の都合のいいタイミングでソケットを開ける状態にしておくということは、デバイス側は常にIP通信が行える状態を保持するため、3G/LTEを常にアクティブな状態にしておく必要があり、(バッテリーで稼働するデバイスの場合、)消費電力に大きな影響を与えること。
この辺の、通信プロトコルやルーティングの選択がデバイスのバッテリーに効いてくる、みたいなところはIoTっぽさがありますね。
ArduinoでCANのテレメトリ with LTE-M Shield + SORACOM
仕事でCANを扱うことになりそうだったので予習を兼ねて自分の車の位置情報とエンジンの回転数、速度をクラウドにアップロードして可視化してみるというのをやってみた。
作ったものの全体像は以下のようなイメージ。クルマに載せるデバイス(canduinoと命名)はエンジンの回転数と速度をOBD2コネクタ経由でCANから、位置情報をGPSモジュールから取得し、Unified Endpoint経由でSORACOM Harvestに格納し、SORACOM Lagoonで可視化している。間にSORACOMが提供するバイナリパーサーという機能を挟むことによって、canduinoから送信されたバイナリをJSON化している。

デバイスの見てくれはこんなかんじ。クルマのUSBコネクタから電源をとっていて、DB9はOBD2コネクタにつながっている。LTEのアンテナの先っぽにGPSモジュールを巻きつけているのは、いちばんショートしなさそうな場所をさがした結果w


最終的にこんなかんじにSORACOM Lagoonで可視化。首都高で有明から箱崎、C1外回りを通って早稲田まで移動。10秒に1回くらい位置情報を送ってるんだけどなんか荒い。地図の問題なのかデータの問題なのかは今回は検証していない。エリアチャートは上段が時速で下段がエンジンの回転数。

CANとは
CANとはControl Area Networkの略称で、クルマの車内ネットワークなどに利用されるBUSの規格、つまりTCP/IPでいうとL2相当の技術。特徴としては、CANにつながるノードたちは自分のデータに対してCAN IDというIDを付与しそれぞれ一定の周期でBUSに流し(ブロードキャストし)ているということ。データがほしいノードは、BUSに流れてくるデータを受信し、あらかじめ知らされているCAN IDのパケットだけをフィルタリングして処理をしていく。CANのパケットは非常に単純で、CAN IDが11bitもしくは29bit、ペイロードは等しく8byteの長さになっている。
クルマで利用される場合は、このBUSにエンジンの回転数やスロットルの開き具合などいろいろな情報がリアルタイムに流れている。もちろん、データ読み取りだけでなく命令の送信などにも使われているので、これを使うことでドアのロックを外せちゃったりもする。らしい。ただし、CANが定義するのはあくまでパケットのフォーマットとそのやりとり手法のみであって、パケットの中身については定義を提供していない。実際、クルマのCAN BUSを流れるパケットは、メーカーや世代、車種ごとにさまざま、かつプロプライエタリである。クルマのチューニングショップがやっているエンジンの燃焼タイミングの最適化なんかは、きっとがんばってこれをリバースエンジニアリングして、CANによる設定の上書きなどしているんだと思う。CANのデータ解析については結構いろんなひとがやっているのでこんなプロジェクトがあったりもする(例がMazdaなのは自分の車がそうだから)。CAN BUSに例えばどんなデータが流れているか興味があるひとは見てみるといいと思う。
CANってなに?の詳細についてはこちらのリンクをみてもらうのがいいかなと思う。いままでいろいろなウェブサイトでCANとは?を調べてみたけど、これがいちばんわかりやすかった。
デバイスを作る
デバイスのベースにはArduino Unoに、その上に順番にSeeedのCAN-BUS Shield、SORACOMのLTE-M Shieldをかぶせている。あとは秋月電子のGPSモジュールをいちばんうえに。最終的なデバイスの見た目はこんなかんじ。

CAN-BUS Shieldについてググるともうひとつ、SparkFunのGPSモジュールを接続できるシールドが見つかるのだけど、このCAN BUSはなんですか?ArduinoでCAN BUSモジュールを使いましょう!というブログがとてもわかり易くCANについて説明してくれていたのでこちらを使ってみることに。なお、このブログのいいところはOBD2とCANの違いについても説明してくれているのでとてもよかった(CANもOBD2についてもそのくらい素人です)。あともう一点このシールドがよかったのは、DB9コネクタと2本線の端子台どちらでもCANが使えること。ひとまず2セット買っておけば、実際のクルマに繋がなくても開発ができる。さらに言えば、あとでわかったことだけど、SeeedのモジュールはハードウェアレベルでのCAN IDフィルタリングの機能を実装してくれているので、ソフトウェア側でフィルタリング書かなくていいので便利。
モノが揃ったので組み立てて、SeeedやSORACOMの提供してくれているサンプルコードをそれぞれ単体で動かすところまではサクッといったんだけど、CAN経由で取得したデータをLTEでアップロードしようとするとうまく動かない。エラーも吐かない。たぶんCANとLTEのシールドでピンが被ってるんだろうなと回路図とかいろいろ調べてみると、あたりっぽい。CANは9,11-13、LTEは10-11がほしそうで、ピン11が被ってる。ミソとかモシってなんだよ~とかぼやきながら(SPI初めて触ったのです)Seeedのwikiを見るとCANのほうはピンアサインの変更にパターンカットが必要そう。一方、LTE-M Shieldのほうは配線だけで変更できそうなのでこちらを変更することにして、結局3と4を使う形に。
GPSモジュールも含めて、最終的なArduinoから見た接続は以下のような感じ(たぶん)。

なんとか動くようになったのでOBD2とDB9の変換ケーブルを使ってドキドキしながらクルマにつなげてみる・・・!
SORACOM Harvestにデータアップロードできたじゃん!!!!1
別のスケッチを使って内容をシリアルコンソールにダンプしてみるとこんなかんじでじゃんじゃんCANのデータフレームが流れてくる。
0000.092 RX: [00000000](00) 00 00 00 00 00 53 56 570000.192 RX: [00000000](00) 00 00 00 00 00 53 56 580000.292 RX: [00000000](00) 00 00 00 00 00 53 56 590000.394 RX: [00000000](00) 00 00 00 00 00 53 56 5A0000.494 RX: [00000000](00) 00 00 00 00 00 53 56 5B0000.594 RX: [00000000](00) 00 00 00 00 00 53 56 5C0000.695 RX: [00000000](00) 00 00 00 00 00 53 56 5D0000.796 RX: [00000000](00) 00 00 00 00 00 53 56 5E
CANのデータフレームを読むにはメーカーなどが提供するビットの読み取りルールが必要になるので「うん、まあSORACOM Harvestまでデータとんだし、まあ今回はここらへんまでかな・・・」と思っていたけど、もう一歩踏み込んでみることに。
CANIDについて調べてみる
「mazda canid」とググってみるとさっそくこんなページ(前述のやつ)に行き当たる。
「おおおお!」と思って手元のダンプしたデータと突き合わせてみるが、実際に流れているデータのCAN IDはこちらの表にぜんぜん見当たらない。表の最終更新日時が2016/03/13なのでしょうがないかなーと思いながらもうすこしググっているとこんな情報に突き当たる。
曰く
0x202 "Bytes 0,1" | "Bytes 2,3" | "Bytes 4,5" | "Bytes 6,7"
Engine RPM x4 | "Vehicle speed, km/h x100″ |"Throttle position, TPS% x 640" | Unknown
とのこと。ひとまずこのとおりにCANID:202のメッセージをデコードしてみると・・・

読めた!青いグラフがエンジンの回転数で、目盛りは左側。赤が速度で目盛りは右側。家の周りをぐるっと一周走ってきた感じなので、速度はときどき0になったり(信号待ち)しながら、最大で40km/hくらい。回転数も750くらいで下限があるので、アイドルのときのことだろう。また、青と赤の時系列的推移もだいたい一致する。(エンジンの回転数がときどき0になっているのはアイドリングストップのため。)
Disclaimar
ここまで読んでいただけたらわかると思うけど、このCANパケットのデコードは「ググって見つけた情報をそのまま使ってみたら動いた」という話なのであしからず。併せて、情報をオープンにしてくれているみなさまには大変感謝。
GPSモジュールとSoftwareSerialでハマる
CANからデータ読んでクラウドに送信して、それが読めることがわかってきたので、こんどはデバイスにGPSモジュールを追加してみる。
まずハマったのが、SoftwareSerialが複数になる点。今回の構成だと、Arduinoからみてハードウェアシリアルで母艦のWindowsとつながっていて、SoftwareSerialでLTE-M Shield、GPSモジュールとつながっている(CAN ShieldはSPI)。
オフィシャルドキュメントには必要に応じて`listen()`を呼べばいいよと書いてあるが、これだとどうもうまく行かない(LTEの通信はうまくいくが、GPSモジュールのデータが読めない)。いろいろ調べていると(さまよいすぎてURLを見失ったが、Arduino Forumでこのトピックについてすごくわかりやすくて網羅的な解説をしてくれている一がいた。URL見つけたら追記する。)、以下のことがわかった。
- ArduinoのSoftwareSerialは、複数のインスタンスがあっても、受信バッファはひとつ
- listen()はこの受信バッファを切り替えるメソッド
- listen()すると受信バッファがクリアされる
- なお、受信バッファは64byte
この特性を理解したうえでこんどはGPSモジュールのマニュアルを読んでいると「このモジュールはデフォルトで1Hzで位置情報を送信する」ということがわかってくる。つまり、GPSモジュールと接続されているSoftwareSerialのポートをlistenし始めてから1秒待たないと情報が揃わない可能性があると。ということでざっくり以下のようなコードを書いたらうまく情報が得られるようになった。
gpsSerial.listen();
delay(1000);
while (gpsSerial.available() > 0) {
// データを読み取っていろいろ処理
}
このGPSモジュールの取り扱いについては下記のブログに大変お世話になりました。ありがとうございます!
クラウド側でデータを受け取って処理する
CANとGPSのデータが取れるようになったので、あとはそれをクラウドに送っていい感じに処理してやればいいというフェーズに。ちなみにデータのパースや各種処理をデバイス側でやるという選択肢は、エッジ側に処理やロジックを持たせなくないので、今回は考えない。ということでデバイスは、おめあてのCANIDのメッセージを受け取るごとに以下の情報をバイナリとしてそのままクラウドに送信する。緯度と経度を100倍してintとして扱っているのはArduinoのコード的に扱いやすいから。(後述のSORACOMのBinary Parserで1/100して取り扱う。)
- CANID(char array 4byte)
- CANペイロード(byte array 8byte)
- 緯度を100倍した値 (int 4byte )
- 経度を100倍した値(int 4byte)
CANとGPSを読んでひとつのバイナリとしてデータを送信する最終的なデバイス側のコードは以下のとおり。
SORACOMにはBinary Parserという素敵な機能があって、固定長のバイナリを任意にパースしてJSON化することができる。上記のコードから送信されるデータを受け取るために、今回は以下のようなパーサーを定義した。詳細に興味をもってくれた方はこちらのリファレンスを見ていただければと思うが、下記のパーサーを通すと・・・
canId:0:char:4 rpm:4:uint:16:/4 speed:6:uint:16:/100 latitude:12:int:16:/100 longitude:14:int:16:/100
デバイスからから送信されたバイナリ(16進数で表記)は・・・
30323032000000322D0000
こんなかんじにパースされてSORACOM Harvestに転送してくれる。(上記のバイナリのCANペイロードと位置情報は適当なものなので注意)
{"canId":"0202","rpm":776.75,"speed":3.05,"latitude":35.71,"longitude":139.73,"binaryParserEnabled":true}
出来上がった!
クラウドにJSONでデータが保存されれば勝利!!!!今回はSORACOM Harvest + SORACOM Lagoonで可視化を実現しているが、SORACOM BeamやSORACOM FunnelでAWSやGoogle Cloudに転送していろいろ処理してやることももちろん可能。ということで今回はいったんここまで。
このさき
ちなみに今回は、「Mazdaの0x202というCAN IDのメッセージ(と、GPSによる位置情報)を読み取ってクラウドに送信する」というデバイス側のコードを書いているが、もう一歩すすめるのであれば、読み取るCANIDをクラウドから取得してそのデータを送信する、くらいまでもっていけるといいなと思っている。
かのクリーンアーキテクチャでは「インフラストラクチャに1行でも依存したコードは”ファームウェア”だ!」と宣言されているので、今回わたしの書いたコードはMazda車の(しかも特定の世代や車種に依存した)ファームウェアということになる。よりクイックにいろいろなデータを試験的に収集することができるようになるためには、「どのデータを取得する」みたいな部分を外部から注入できるようになるといまどきっぽいね。(依存性の注入なんで「いまどき」どころではない話だが、物理デバイスの世界ではまだまだ新しい。気がする。)このへんは、例えばSORACOMのメタデータサービスを使えば実装できると思っているが、今回はてがまわっていないのでまた今度。
S+ Camera Basic + Deep SORTでリアルタイムトラッキング(前編)
今日はSORACOM Advent Calendar 2020のネタとして、S+ Camera BasicでDeep SORTを動かすことに挑戦してみたいと思います。
先にお断りしておきますと、残念ながら今日の時点ではS+ Camera Basic実機で動かすところまでたどり着いておらず、以下のようなシリーズ物として綴っていく予定ですorz
1. Deep SORTについてのおさらいと、まずはMacでas isで動かしてみる (←このポスト)
2. S+ Camera BasicでDeep SORTを動かす
Deep SORTってなに?
Deep SORTは映像のなかに映っている、複数のオブジェクト(例えば人)を同時に、かつ連続的にトラックしていくための手法のひとつで、Simple Online and Realtime Tracking with a Deep Association Metricというタイトルで論文(Wojke, Bewley, Raulus. (2017). Simple Online and Realtime Tracking with a Deep Association Metric)が投稿されており、この手法を利用することで、例えば通行量調査を実装することができます。画面の左から移動してきた人が、画面中央のボーダーラインを越えたらカウントする。また右から左に向かって移動する人に対しても同様の処理を行う、といったイメージで。

(画像参照元: https://motchallenge.net/vis/MOT16-04/det/ )
移動体のトラッキングは単純なObject Detectionと違い、前のフレームに映っていた「あのひと」と現フレームに映っている「このひと」が同じ人かどうかを評価、同定してやる必要があります。場合によってはトラッキング対象が一時的に物陰に入ってしまったりといったような課題も出てきます。この種の問題はMulti Object Trackingと呼ばれ、MOT Challengeというコンペティションも開かれていて、上記の画像はこのMOT Challengeのデータセットのひとつです。
Deep SORTも、MOT16のデータセットに対して以下のような成績をマークしていると前述の論文中で語られています。一番したの行がDeep SORTによるデータです。

(当図表は論文より)
S+ Camera Basicとは?
S+ Camera Basic(サープラスカメラ、と読みます。以下、S+ Cameraと略します。)はソラコムが開発、販売するプログラマブルなネットワークカメラデバイスです(コネクティビティはもちろんSORACOM Airです!)。S+ CameraはSORACOM Mosaicという「エッジデバイス統合管理サービス」によって管理され、通信回線を通じてアプリケーションデプロイやシステムメンテナンスが行えるため、一度現場に配備したあとでも簡単にアプリケーションの更新が可能です。
このカメラの特徴としては、電源を挿すだけでオンラインになり、書き込まれたプログラムが動作し始める、プログラムはPythonで開発できる、デプロイはSORACOM Mosaic経由でオンラインで行えることが上げられます。つまり、アプリケーション開発者はPythonでの画像処理の部分、言い換えればビジネスロジックの開発にリソースを集中することができます。
なぜS+ Camera BasicでDeep SORTを?
わたしは2020年現在、株式会社ソラコムでソリューションアーキテクトとして仕事をしており、S+ Camera Basicを使ったIoTアプリケーションの設計や開発をされるお客様のお手伝いをしています。カメラを使ったIoTのユースケースとして多いのが、OCRによる文字読み取りやメータの読み取り、そして混雑度の数値化が挙げられます。混雑度の数値化については、単純なやり方としてはObject Detectionを使って、画面内に映っている人の人数を数えるというやり方があり、これはこれで有効なケースがあります。一方、人の流れを把握したい、例えば人がどこから入ってきてどこに抜けていった、というようないわゆる人流みたいなところまで取りたくなってくると、カメラでやろうとすると今回の議論にあるようなDeep SORTのような手法が必要になってきます(カメラ以外でやるなら、人の通るところにセンサーを設置していくという方法もあります。これはこれで、多くの人を同時に(かつ別々に)センシングするのが難しい、などの考慮事項もあります)。これまで仕事でDeep SORTの話をすることはちょいちょいあったのですが、自分でしっかり使い込んだことがなかったというのがなんとなく引っかかっていたので、今回、がっつり触っておこうと思ったというのが今回のモチベーションです。あとはサンプルコードとして公開しておけば後々の自分の仕事も楽になるかなというのもあり笑
Deep SORTの処理概要
さて、中身について少し見ていきましょう。前述のような問題をDeep SORTはざっくり以下のようなアプローチで解決していきます。
- 画面内に映っているものをObject Detectionする
- 検出されたオブジェクト群と前のフレームのオブジェクト群を「前フレームまでの移動量をもとに計算した現フレームでの予測位置範囲」と「見た目の類似性」という、主に2つの情報をもとに比較、同定していく
位置の予測についてはカルマンフィルタ、見た目の類似性についてはベクトル化した対象画像のコサイン類似度を使って計算をします。
1フレームごとにDeep LearningベースのObject Detectionを行い、発見された各オブジェクトに対してCNN等を活用したベクトル化、そして前フレームのオブジェクト群とのカルマンフィルタとコサイン類似度の比較を行うということになりますので「重い処理」と言っても差し支えないと思います。それでもMOT16のなかでは速いほうの部類にあるようですが(前出の図表中のRuntimeの比較にも現れていますね)、Raspberry PiのCPUだけで現実的なリアルタイムトラッキングを行うには厳しいでしょう。
ひとまず動かしてみよう
ではまずは動かしてみましょう。論文の著者であるNicolai Wojkeによる参考実装もありますがここでは下記の実装を利用してみたいと思います。詳細は後述していきますが、Object Detection部分をCoral Edge TPUのサポートを受けるTFLiteへの切り替えがしやすそうな実装だったことが理由です。
Tensorflow + CPU(Mac Book Pro。M1ではない) で動かしてみました。いちばん処理量の多いであろうObject DetectionのアルゴリズムはYOLOv4です。1.2〜1.3FPSという感じですね。やはりなかなか重い。Mac Book Proでこのレベルですから、S+ Camera BasicのコントローラであるRaspberry Pi4では相当厳しいでしょう。
次にObject Detectionの部分を前述のようにCoral Edge TPUサポート付きのTFLiteによるMobileNet SSDv2に切り替えてみました。10FPS前後出るようになっていますね!Coral Edge TPUはRaspberry Pi4でも動作がサポートされていますし、S+ Camera Basicでも動作確認が取られていますので、これは期待できそうですね。
今日はここまで。次回はS+ Camera Basicで動くようにしてみましょう
今日はこのへんで。年内にS+ Camera Basicで動かすところまで行けたらなと思っています!上記、Coral Edge TPUでDeep SORTを動かしているコードも、次回あたりに向けて公開はしていきたいと思っています。(いまはかなりmessな状態なのでちょっと無理ですw
9/26 15kmペース走 4'00/km
いままでで一番長いペース走。ミズノのサブスリーメニューで一番きつそうなやつ。5kmを越えたあたりから余裕が出てきた。最後の1kmのそれなりにスパート効いた。
先週に引き続き、やっぱり(終わったあと)お腹壊した。負荷に対して腹筋が足りないのかな・・?
コンディション
- 22℃
- 82%
- 北北東の風 10.4km/hour
タイム
心拍
- 平均: 174
- 最大: 192